We’re all so busy being practical that we don’t have time to be intelligent

Amnon H. Eden
Sapience.org
Research
Active research
- Machine Learning
- Artificial General Intelligence
- Utility Value of Currencies (Entropy)
- Computer trading (algotrading)
- Cryptocurrency & Blockchain technology
My research currently focuses on disruptive technologies or major paradigm shifts brought about by new technology, such as von Neumann (programmable) computers, computer trading and superintelligence.
Disruption is taken to be an interdisciplinary area of research combining computing, philosophy, artificial intelligence, engineering, social sciences, and future studies, as inspired by the work of John von Neumann, Alan Turing, and Alvin Toffler. In particular I am interested in that transformative effects of increasingly intelligent AI.
Science currently has three frontiers: the very big, the very small, and the very complex.
Published research
I read computer science in Tel Aviv University, writing my dissertations on software design and machine learning, but as student in the Interdisciplinary Program I was also given the opportunity to maintained active interest in other disciplines, including brain sciences, cognitive psychology, ontology, and semantics.
My published work contributed to subjects in software engineering, artificial intelligence, and the philosophy of computer science.
It has long been my personal view that the separation of practical and theoretical work is artificial and injurious. Much of the practical work done in computing, both in software and in hardware design, is unsound and clumsy because the people who do it have not any clear understanding of the fundamental design principles of their work. Most of the abstract mathematical and theoretical work is sterile because it has no point of contact with real computing.
-
Theory and practice of software design, architecture, modelling, visualisation, and evolution;
Formal methods: quantifying and formalising design traits; theory and practice of formal verification
- .
- Design Patterns
- Development Tools
- Formal Methods
- Object-Oriented Programming
- Software Engineering
- Software Modelling
- Software Visualization


Popular software modelling notations visualize implementation minutiae but fail to scale, to capture design abstractions, and to deliver effective tool support.
The first version of the modelling language was named LePUS by its inventor, Dr Eden. The LePUS notation only modelled design patterns. LePUS3, the language of Codecharts, was developed by Dr Eden with his research students Dr Notis Gasparis and Dr Jonathan Nicholson.
The formal design description language of Codecharts was tailored to—
- Visualize the building–blocks of object–oriented design
- Create bird’s–eye roadmaps of large programs with minimal symbols and no clutter
- Model blueprints of patterns, frameworks, and other design decisions
- Be exactly sure what diagrams claim about programs and reason rigorously about them
LePUS3, the language of Codecharts, also satisfies the following requirements:
- Scalability: To model industrial-scale programs using small Codecharts with only few symbols
- Automated design verifiability: To allow programmers to continuously keep the design in synch with the implementation
- Visualization (only LePUS3): To allow tools to reverse-engineer legible Codecharts from plain source code modelling their design
- Pattern verification: To allow tools to determine automatically whether your program implements a design pattern
- Abstraction in early design: To specify unimplemented programs without committing prematurely to implementation minutia
- Genericity: To model a design pattern not as a specific implementation but as a design motif
- Rigour: To be rigorous and allow software designers to be sure exactly what Codecharts mean and reason rigorously about them
- .
- Design Patterns
- Development Tools
- Formal Methods
- Object-Oriented Programming
- Software Engineering
- Software Evolution

Design patterns are not programs but blueprints of an implementation, templates which describe the correlations and collaborations between generic participants in a program. Modelling them therefore requires an appropriately generic language.
We define Codecharts, a visual language for modelling the static (decidable) aspects of design patterns, and demonstrate how to verify whether a given Java implementation satisfies the specification of the pattern.
- All
- Development Tools
- Software Engineering
- Software Visualization


Visualising object-oriented design (OOD) poses several challenges, for example:
- How can the constructs of OOD be best visualised?
- How much of the program should be visualised?
This line of work demonstrates the answers given to these questions.
- .
- Formal Methods
- Software Engineering
- Software Evolution


Everyone knows that software needs to be flexible. We also know that design patterns and architectural styles improve the ability of programs to evolve. But how can flexibility can be measured?
Our work suggests an objective measure for flexibility, called “evolution complexity”. We use the measure to compare the flexibility of design alternatives, thereby providing a robust definition of flexibility.
For example, we know that adding a new ‘Visitor’ class to a program that implements the Visitor pattern is easy, but now we can prove that the change has low evolution complexity.
We also show that flexibility is relative to a particular class of changes. For example, while it is easy to add a ‘Visitor’, it’s hard to add an operation. We demonstrate that this change is hard by showing that adding an operation to an implementation of the Visitor pattern has high evolution complexity.
- All
- Formal Methods
- Software Architecture
- Software Design
- Software Engineering
- Software Evolution

What is the difference between architecture and design? This distinction is important since the choice of architecture has strategic and far-reaching implications over the implementation and therefore must be made early in the development process, whereas design decisions have localized effect and must be deferred to a latter stage in the process.
We distinguish between three abstraction strata in software design statements:
- Strategic statements include programming paradigms and architectural styles
- Tactical statements include design patterns
- Implementation statements include class diagrams
We define criteria of distinction in mathematical logic and present the Intension/Locality Hypothesis:
- The class of non-local statements (NL) contains Strategic statements;
- The class of local and intensional statements (LI) contains Tactical statements;
- The class of local and extensional statements (LE) contains Implementation statements.
This distinction allows us to prove the Architectural Mismatch Theorem, which formalizes the notion of architectural mismatch (Garlan, Allen & Ockerbloom 1995).
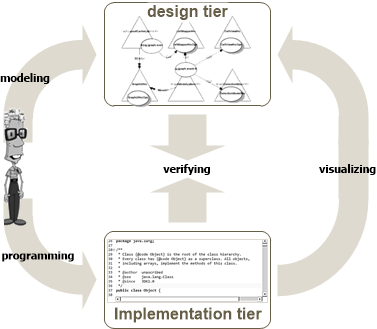
Inconsistency between design and implem entation is a major problem for most programmers. Conflicts are common because there are no effective tools for detecting them. Original design documents are a hassle to update (and nobody bothers with that). Absence of current and accurate design documentation results in software that is unpredictable and poorly understood.
Round-trip engineering tools support an iterative process of detecting conflicts and resolving them by changing either the design or the implementation.
A Toolkit we developed, the Two-Tier Programming Toolkit, supports a round-trip engineering of native Java programs without interfering with any existing practices, tools or development environments, thereby posing a minimal barrier on adoption. The Toolkit includes a user-guided software visualization and design recovery tool, which generates Codecharts from source code. A ‘round-trip’ process is possible because Codecharts visualizing source code can be edited to reflect the intended design, and the Verifier can detect conflicts between the intended and as-implemented design.
Our work has demonstrated how the Toolkit effectively helps to close the gap between design and implementation, recreate design documentation, and maintaining consistency between design and implementation.
- All
- Development Tools
- Software Engineering

Suppose that [special and general relatively, automobiles, airplanes, quantum mechanics, large rockets and space travel, fission power, fusion bombs, lasers, and large digital computers] had all been presented to mankind in a single year! This is the magnitude of “future shock” that we can expect from our AI expanded scientific community.
-
Machine learning; disruptive impact; superintelligence
- .
- Artificial Intelligence
- Machine Learning

Humans learn to recognize birds and chairs without explicit definitions. ‘Natural concepts’ are noisy categories which have no crisp boundaries, yet humans learn identify them quickly and easily. Can artificial intelligence perform the same task?
Creating an agent capable of identifying natural concepts effectively can become possible by building upon lessons learned from the human ability to perform this task.
Our line of investigation borrows heavily from the interdisciplinary literature on concept formation and models of representation, in particular cognitive psychology and the philosophy of mind corpora.
- .
- Artificial Intelligence
- Disruptive Technology
- Superintelligence

Consider intelligence as the general ability to solve problems and increase utility that animals and machines have, not only present humans. It would be naive to assume Homo Sapiens Sapiens has the highest intelligence possible or anything remotely close to it. It is much more likely that much more intelligent beings could exist.

An agent whose intelligence exceeds that of the brightest person is said to be superintelligent. It is hypothesized that intelligence amplification (eg cognitive enhancement) may lead to superintelligent posthumans. Others have argued that self-improving artificial intelligence can also become superintelligent, possibly in a process of intelligence explosion.
Given the advances both in intelligence amplification (IA) and artificial intelligence (AI), the question many ask is which one will arrive first?
It was not made for those who sell oil or sardines
-
Ontology, epistemology, and paradigms of computer science
- .
- Philosophy of Computer Science


Computer science is a broad discipline. Theoretical computer science is very mathematical, whereas software development has all the hallmarks of an engineering activity. Further facets merge with psychology and cognitive science and applications are found throughout the physical sciences and engineering.
The philosophy of computer science is concerned with conceptual issues that arise by reflection upon the nature of computer science. The topics covered reflect the latter’s wide range: What kind of discipline is computer science? What are the roles of design and experimentation? What role is played by mathematics? What do correctness proofs establish? These are only a few of the questions that form the body of the philosophy of computer science.
Our entry on the philosophy of computer science in Stanford Encyclopedia of Philosophy attempts to cast these questions in the context of existing philosophical issues and shed light on the answers that the various branches of computing may offer.
- .
- Ontology
- Philosophy of Computer Science

Is computer science a branch of mathematics, an engineering discipline, or a natural science? Should knowledge about the behaviour of programs proceed deductively or empirically? Are computer programs on a par with mathematical objects, with mere data, or with mental processes?
Public debates on the answers to these questions reveal three very different perspectives over methodological, ontological, and epistemological issues:
- The rationalist paradigm, which was common among theoretical computer scientists, defines computer science as a branch of mathematics, treats programs on a par with mathematical objects, and seeks certain, a priori knowledge about their ‘correctness’ by means of deductive reasoning.
- The technocratic paradigm, promulgated mainly by software engineers, defines computer science as an engineering discipline, treats programs as mere data, and seeks probable, a posteriori knowledge about their reliability empirically using testing suites.
- The scientific paradigm, prevalent in the branches of artificial intelligence, defines computer science as a natural (empirical) science, takes programs to be entities on a par with mental processes, and seeks a priori and a posteriori knowledge about them by combining formal deduction and scientific experimentation.
If we knew what it was we were doing, it would not be called research, would it?